Iceberg Format
Iceberg format refers to Apache Iceberg table, which is an open table format for large analytical datasets designed to provide scalable, efficient, and secure data storage and query solutions. It supports data operations on multiple storage backends and provides features such as ACID transactions, multi-version control, and schema evolution, making data management and querying more flexible and convenient.
With the release of Iceberg v2, Iceberg addresses the shortcomings of row-level updates through the MOR (Merge On Read) mechanism, which better supports streaming updates. However, as data and delete files are written, the read performance and availability of the table will decrease, and if not maintained in time, the table will quickly become unusable.
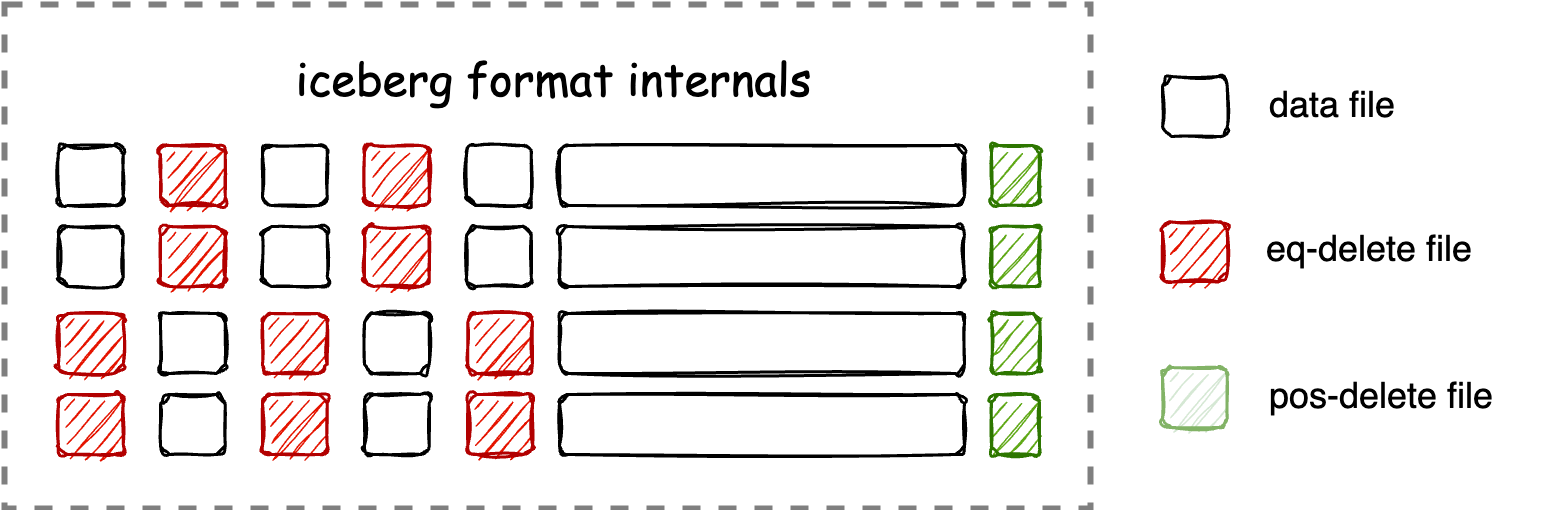
Starting from Amoro v0.4, Iceberg format including v1 and v2 is supported. Users only need to register Iceberg’s catalog in Amoro to host the table for Amoro maintenance. For detailed operation steps, please refer to Managing Catalogs. Amoro maintains the performance and economic availability of Iceberg tables with minimal read/write costs through means such as small file merging, eq-delete file conversion to pos-delete files, duplicate data elimination, and file cleaning, and Amoro has no intrusive impact on the functionality of Iceberg.
Iceberg format has full upward and downward compatibility features, and in general, users do not have to worry about the compatibility of the Iceberg version used by the engine client with the Iceberg version on which Amoro depends.
Amoro supports all catalog types supported by Iceberg, including but not limited to: Hadoop, Hive, Glue, JDBC, Nessie, Snowflake, and so on.
Amoro supports all storage types supported by Iceberg, including but not limited to: Hadoop, S3, AliyunOSS, GCS, ECS, and so on.