This documentation reflects the latest development version and may change before the next official release.
For the latest stable documentation, see 0.8.1-incubating.
Mixed-Hive Format
Mixed-Hive format is a format that has better compatibility with Hive than Mixed-Iceberg format. Mixed-Hive format uses a Hive table as the BaseStore and an Iceberg table as the ChangeStore. Mixed-Hive format supports:
- schema, partition, and types consistent with Hive format
- Using the Hive connector to read and write Mixed-Hive format tables as Hive tables
- Upgrading a Hive table in-place to a Mixed-Hive format table without data rewriting or migration, with a response time in seconds
- All the functional features of Mixed-Iceberg format
The structure of Mixed-Hive format is shown below:
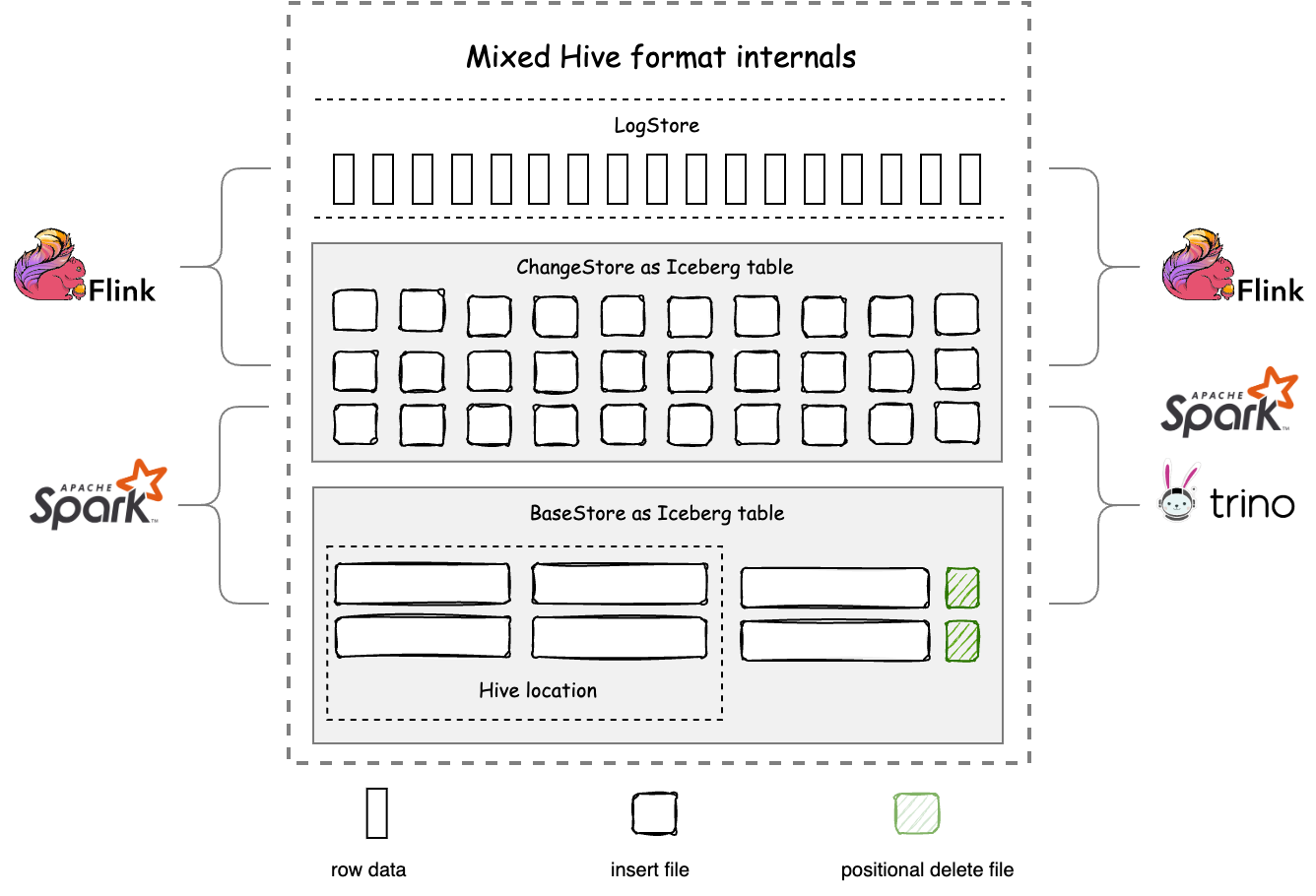
In the BaseStore, files under the Hive location are also indexed by the Iceberg manifest, avoiding data redundancy between the two formats. Mixed-Hive format combines the snapshot, ACID, and MVCC features of Iceberg, and provides a great degree of compatibility with Hive, offering flexible selection and extension options for data platforms, processes, and products built around Hive format in the past.